
Establishing Operational Excellence with a Network Performance Management Platform

Contents
A guide to achieving operational excellence
The path to operational excellence requires streamlining network alerts, escalations, notifications, and root-cause analysis.
Adopt an NPM procurement strategy that favors unified, multifunction platforms over best-of-breed NPM tools from multiple vendors.
Our eBook paper reveals:
- A three-step process for establishing operational excellence
- How successful companies structure their procurement strategy for NPM
- Six critical capabilities to include in NPM assessments
Find a platform that has well defined workflows and unifies all three elements of operational excellence into one dashboard view. Find LiveAction. Get a demo today.
What is Operational Excellence?
In the world of network management, operational excellence is about visibility and efficiency. Network managers should look for opportunities to improve operational awareness while reducing the time and cost associated with network management processes. At a more practical level, network managers can start by finding ways to automate and accelerate the escalation of trouble tickets to network experts while also streamlining network troubleshooting and capacity management tasks.
Three-Step Process for Establishing Excellence
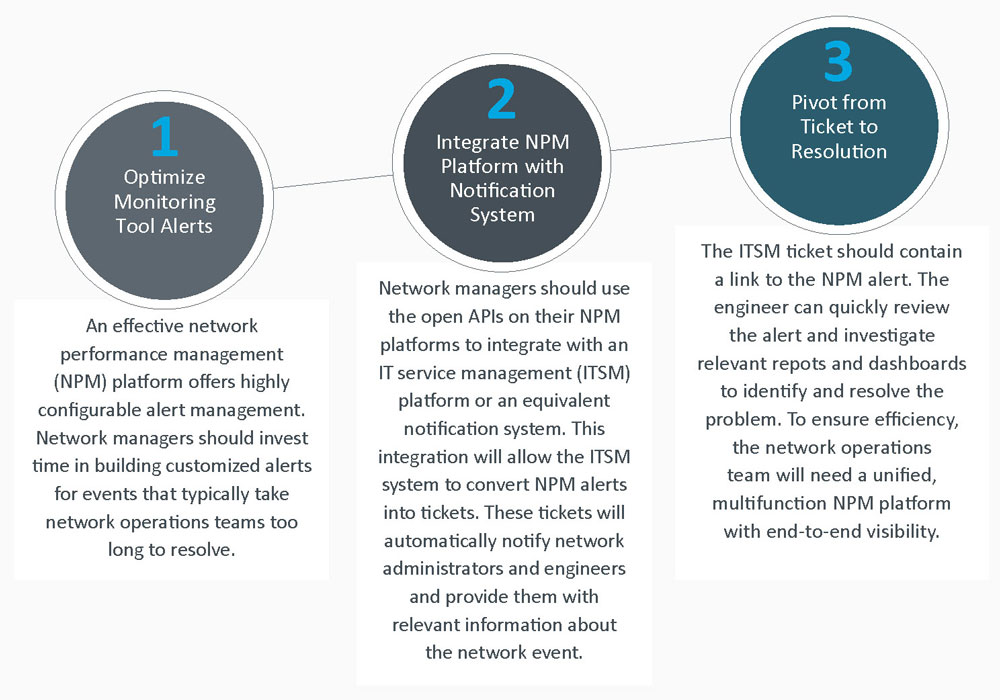
Requirements for Operational Excellence
A Unified NPM Platform
Operational excellence begins with having the right NPM platform. This platform should be able to collect and analyze multiple types of metrics and data and present that analysis via reports, dashboards, and well-defined workflows. Network operations teams often use four or five tools for network monitoring and troubleshooting. To achieve operational excellence, IT organizations may need to consolidate tools. Consolidation will ensure that network managers can collect and analyze the broadest set of metrics and data possible in a unified, multifunction NPM platform.
Removing tool sprawl allows network managers to streamline both alert management and network analysis. Industry analyst research has established that tool consolidation is an industry best practice. Figure 1 reveals that successful network operations teams are more likely to adopt a network management tool procurement strategy that focuses on unified, multifunction platforms. Less successful teams tend to procure best-of-breed network management tools from multiple vendors.1
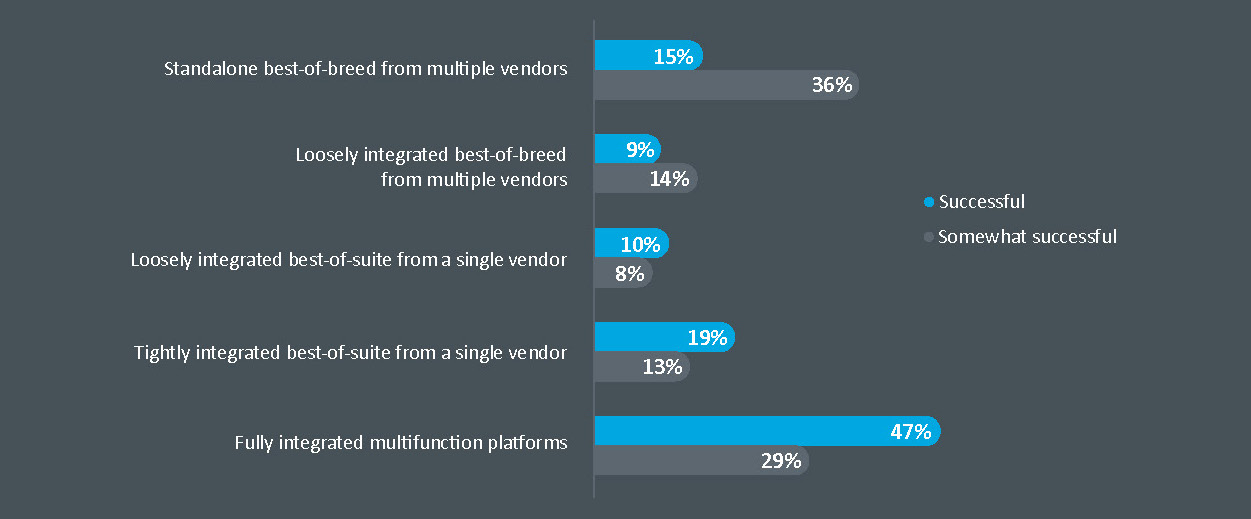
Figure 1. Successful network teams prefer tightly integrated network management tools
1 Enterprise Management Associates, “Network Management Megatrends 2020,” April 2020.
Key NPM Capabilities
When embarking on an operational excellence journey, network managers should make sure their NPM platforms have several key capabilities.
- Network health monitoring. The tool must be able to collect metrics and data that reveal the state of network devices, connectivity, utilization, and traffic flows.
- WAN link utilization reports. These reports should reveal the status of WAN links for all connected sites. This allows network managers to quickly identify whether network trouble associated with a specific site is rooted in WAN connectivity.
- Historical analysis via reporting. These reports can enrich NPM alerts and enable network engineers to quickly identify the root cause of an issue. This reporting should highlight trends, patterns, and anomalies on the network.
- Alert management. Administrators must be able to configure alerts for use cases important to network operations. This requires a variety of alert management customization options so administrators can set up alerts with multiple variables.
- End-to-end visibility. A unified tool should offer domain breadth so all parts of the network can be monitored and managed in one place, from the LAN to the WAN and into the cloud.
- Integration. The NPM platform must be ready to integrate with the incumbent ITSM platform. Many NPM vendors offer out-of-the-box integration with leading vendors, but open APIs with thorough and up-to-date documentation can also facilitate integration if one has a homegrown or niche ITSM solution.
How to Execute Operational Excellence
Operational excellence is all about streamlining common network management processes through platform integrations and workflows. Every network operations team has common use cases and scenarios that could be streamlined as part of an operational excellence initiative. This section illustrations how one can execute across two common scenarios.
Key Scenarios for Operational Excellence
- Fault management.
When an NPM platform detects a network fault, the platform should generate a customized alert that is escalated to the right expert as quickly as possible. The alert notification should give the network expert the information he or she needs to remediate the fault quickly. - Capacity management.
With the right alert management configurations, pattern analysis by an NPM tool will generate capacity alerts. Those alerts should trigger tickets in a notification system that gets the attention of engineers who can adjust the network and prevent trouble.
Fault Management Scenario:
“The network is slow”
Network managers are very familiar with vague complaints about network slowness. It’s essential to respond efficiently to these issues since it can take a very long time to search for the root cause of such a general complaint. However, with the proper configurations and integrations, this process can be streamlined.
1. Configure network performance alerts in NPM platform
Network managers should identify critical devices, interfaces, network paths, and applications. Then, they should configure alerts based on thresholds and conditions associated with these key network elements. For example, they could set an alert threshold for routing tables that fall out of compliance, or they could configure an alert that goes off when voice traffic exceeds thresholds for jitter, packet loss, and latency. That alert could generate information on QoS markings for the relevant voice traffic, giving more context for analysis.
2. Integrate NPM with ITSM to ensure network performance alerts generate notifications
APIs must be flexible and well-documented. They should expose as much as possible in the NPM solution to enable easy transfer of data to the ITSM system. These alerts can forward relevant data on an event, automatically generating a ticket.
The ticket can send out notifications via web UI, email, SMS, APIs, syslog, and other methods. They should be routed to the relevant on-call engineer. Ideally, NPM and ITSM integration will insert a link in the ticket that will take an engineer to the relevant alerts page in the NPM tool.
3. Investigate and explore in NPM to determine root cause of event
When an engineer receives a notification, he or she should click the embedded link to jump to the relevant NPM dashboard views, both canned and customized, to find an overview of the relevant portion of the network. From there, they can review reports enriched with drilldown workflows to find relevant insights.
In this situation, an NPM tool must retain granular data that is accessible from drilldown workflows. Engineers should configure the platform to retain SNMP MIBs and traps, packets, flows, and API calls to ensure that root-cause analysis is possible. This will ensure that everything contextualized, from the NPM alert to the ITSM ticket to the NPM workflows, facilitating a streamlined process of root-cause analysis and remediation.
Capacity Management Scenario:
“WAN utilization is growing”
WAN links are often bandwidth-constrained, especially when an enterprise makes heavy use of real-time applications or transfers large files. It is important to manage this WAN capacity carefully to ensure that digital services are available and performing well.
In this context, network operations teams should focus on revealing any indicators of WAN capacity trouble quickly to relevant stakeholders so that they can take proactive action to prevent network trouble.
1. Review and configure WAN utilization alerts
Network engineers should focus on key capacity data sources, like SNMP and network flows. They should configure alerts for WAN link utilization thresholds, WAN application QoS markings, network health status, application performance, and application utilization. If any of these thresholds are surpassed, the NPM platform should issue an alert.
2. Ensure NPM integration with ITSM enables WAN utilization notifications
APIs must be flexible and well-documented, and they should expose as much data and analysis as possible in the NPM solution to enable easy transfer of data to ITSM. Alerts can forward to ITSM as an event or incident and automatically generate a ticket. Notifications go out to via web UI, email, SMS, APIs, syslog or by other means, routing to the attention of engineers responsible for WAN capacity. Ideally, the integration will insert a link in the ITSM ticket that will take an engineer to the relevant alerts page.
3. Investigation source of WAN utilization alerts in NPM
The network engineer should click from the notification into the alerts page of the NPM solution and review the capacity alert. From there, they can drill down to dashboards and reports to find utilization trends, top application talkers, QoS markers, and other indicators. Then, they can pivot to WAN utilization reports and drill down further to individual interfaces.
Engineers can also review back-in-time reports for more context or to uncover long-term capacity issues. They should check the WAN utilization dashboard of the NPM solution and drill down to relevant reports.
By reviewing all this information, engineers should be able to quickly find the root cause of a pending capacity issue and make adjustments via QoS adjustments or some other configuration.
The Operational Excellence Mission
When signs of trouble emerge, NPM platforms must be ready to…
- Generate insightful alerts
- Push those alerts to an ITSM platform for streamlined escalation
- Provide workflows that take an engineer through an efficient root-cause analysis process
Network operations teams should look for unified, multifunction NPM platforms that can consolidate tool sprawl while offering customizable alert management, open and documented APIs for ITSM integration, and well-defined workflows for fault management and capacity management. These solutions should perform rich data collection, offer dashboards and reports with drilldown capabilities, and support historical data analysis.
This eBook provided a roadmap for operational excellence, but every IT organization has its unique requirements. This is just the starting point. Ask your IT operations vendors how they can support you on your journey toward operational excellence.
Download eBook
Establishing Operational Excellence with a Network Performance Management Platform: LiveAction eBook
Download Your Free LiveNX Trial